
Despite widespread and increasing use of the cloud for data and analytics workloads, it has become clear in recent years that, for most organizations, a proportion of data-processing workloads will remain on-premises in centralized data centers or distributed-edge processing infrastructure. As we recently noted, as compute and storage are distributed across a hybrid and multi-cloud architecture, so, too, is the data it stores and relies upon. This presents challenges for organizations to identify, manage and analyze all the data that is available to them. It also presents opportunities for vendors to help alleviate that challenge. In particular, it provides a gap in the market for data-platform vendors to distinguish themselves from the various cloud providers with cloud-agnostic data platforms that can support data processing across hybrid IT, multi-cloud and edge environments (including Internet of Things devices, as well as servers and local data centers located close to the source of the data). Yellowbrick Data is one vendor that has seized upon that opportunity with its cloud Data Warehouse offering.
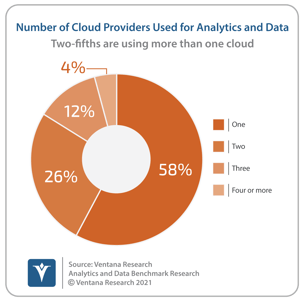
Yellowbrick emerged in 2018, four years after it had been founded, with a high-performance, massively parallel, data warehouse offering designed to exploit flash memory. The offering was at first primarily delivered via an optimized hardware appliance, which remains an option today, but was also quickly made available as a public cloud service. Asynchronous data replication, another key aspect of the product’s functionality, lent itself to a focus on the benefits of replicating data between on-premises and cloud instances, initially for business continuity. As data is increasingly stored and processed across multiple data center, edge and cloud environments, so Yellowbrick has increasingly focused its attention on how the design choices behind Yellowbrick Data Warehouse (including the aforementioned exploitation of flash storage infrastructure and the use of asynchronous data replication) are as relevant to data processing and analytics across hybrid IT and multi-cloud environments as they are to the optimized hardware appliance. The growing requirement for multi-cloud data processing is clear. Almost one-half (49%) of respondents to Ventana Research’s Analytics and Data Benchmark Research are currently using cloud computing for analytics and data, of which 42% are using more than one cloud provider.
 I recently explained the various reasons why data platforms that support hybrid and multi-cloud architectures are attractive to organizations: to safeguard data; meet business continuity, latency and sovereignty needs; and recognize the importance of data platforms offering data-management capabilities that span multiple locations. This has been a core focus of Yellowbrick’s recent product enhancements, particularly as it looks to address growing demand for distributed cloud architecture, which is characterized by the deployment of cloud software and infrastructure in on-premises locations, including centralized data centers and edge environments, as well as the utilization of containers and container orchestration systems, such as Kubernetes, to automate software deployment, scaling and management.
I recently explained the various reasons why data platforms that support hybrid and multi-cloud architectures are attractive to organizations: to safeguard data; meet business continuity, latency and sovereignty needs; and recognize the importance of data platforms offering data-management capabilities that span multiple locations. This has been a core focus of Yellowbrick’s recent product enhancements, particularly as it looks to address growing demand for distributed cloud architecture, which is characterized by the deployment of cloud software and infrastructure in on-premises locations, including centralized data centers and edge environments, as well as the utilization of containers and container orchestration systems, such as Kubernetes, to automate software deployment, scaling and management.
Yellowbrick’s ability to address distributed cloud was boosted in 2021 by its embrace of Kubernetes for the deployment, scaling and management of containerized applications. Support for Kubernetes is a fundamental enabler of the company’s ability to enable the deployment and portability of workloads in and across multiple environments. This includes on-premises data centers (utilizing the company’s own Andromeda optimized hardware or private cloud Kubernetes deployments), as well as public cloud (both managed software-as-a-service (SaaS) and self-managed Kubernetes services) and edge deployments (on Andromeda or cloud provider edge infrastructure offerings).
Adoption of private cloud infrastructure delivered by public cloud providers (such as Amazon Web Services’ Outposts, Microsoft’s Azure Stack, and Google’s Distributed Cloud) is nascent, but it is growing. As my colleague Dave Menninger asserts, by 2024, one-third of organizations will be investing in distributed cloud infrastructure to standardize environments used in the public cloud, as well as in on-premises data centers and at the edge.
 Support for Kubernetes is important for workload orchestration and portability. It does little to address data management in a distributed cloud environment, however. As such, the launch of Yellowbrick Manager was also critical to the company’s distributed cloud plans. Yellowbrick Manager is a web-based management interface designed to provide a unified control plane for all Yellowbrick Data Warehouse instances, wherever they might be deployed. The offering is initially aimed at data engineers and developers but is intended to be the company’s long-term unified management interface for database administration as well. Key functionality includes data loading, workload management (including cluster resource utilization, query control, query mapping and query prioritization), as well as data exploration and SQL development. In combination, support for Kubernetes and Yellowbrick Manager create an abstraction between the distributed data layer and the underlying infrastructure, providing consistency across multiple cloud providers, data centers and edge locations, reducing the potential for overreliance on an individual cloud provider or consumption model.
Support for Kubernetes is important for workload orchestration and portability. It does little to address data management in a distributed cloud environment, however. As such, the launch of Yellowbrick Manager was also critical to the company’s distributed cloud plans. Yellowbrick Manager is a web-based management interface designed to provide a unified control plane for all Yellowbrick Data Warehouse instances, wherever they might be deployed. The offering is initially aimed at data engineers and developers but is intended to be the company’s long-term unified management interface for database administration as well. Key functionality includes data loading, workload management (including cluster resource utilization, query control, query mapping and query prioritization), as well as data exploration and SQL development. In combination, support for Kubernetes and Yellowbrick Manager create an abstraction between the distributed data layer and the underlying infrastructure, providing consistency across multiple cloud providers, data centers and edge locations, reducing the potential for overreliance on an individual cloud provider or consumption model.
Yellowbrick is operating in a crowded and highly competitive field and is by no means alone in recognizing the need for data-processing capabilities that span hybrid and multi-cloud environments. The company is proactively addressing the long-term implications of distributed cloud, however, recognizing that the ability to manage workloads, resources, data and queries across a distributed cloud environment is a competitive differentiator against vendors that can merely offer disconnected data platforms running in multiple locations or reliance on cloud infrastructure offered by a single provider. I recommend that enterprises exploring the options for data processing in distributed cloud environments should evaluate Yellowbrick’s Data Warehouse.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








