

I recently described the growing level of interest in data mesh which provides an organizational and cultural approach to data ownership, access and governance that facilitates distributed data processing. As I stated in my Analyst Perspective, data mesh is not a product that can be acquired or even a technical architecture that can be built. Adopting the data mesh approach is dependent on people and process change to overcome traditional reliance on centralized ownership of data and infrastructure and adapt to its principles of domain-oriented ownership, data as a product, self-serve data infrastructure and federated governance. Many organizations will need to make technological changes to facilitate adoption of data mesh, however. Starburst Data is associated with accelerating analysis of data in data lakes but is also one of several vendors aligning their products with data mesh.
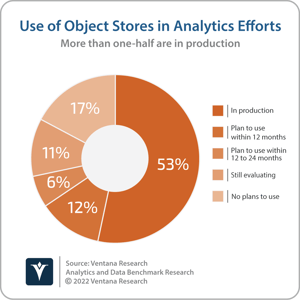
%20(1)-png-2.png?width=300&name=VR_Data_2022_Coverage_Logo%20(3)%20(1)-png-2.png) Starburst was founded in 2017 to build a commercial business around the Trino distributed SQL query engine (formerly known as PrestoSQL). The company was originally focused on supporting customers using Trino to perform SQL-based data analysis in Apache Hadoop and object storage environments. The latter has been a significant growth engine, with more than one-half (53%) of participants in Ventana Research’s Analytics and Data Benchmark Research currently using object stores in their analytics efforts and an additional 18% planning to do so. Additionally, Starburst has built a range of functionality around Trino to create a broader data consumption layer, with capabilities for data access, data management, advanced analytics, security and hybrid- and multi-cloud connectivity. The company has grown rapidly and now has a roster of customers including FINRA and DBS Bank in financial services, Assurance in insurance, Emis in healthcare, and Zalando, Carrefour, DoorDash, and GrubHub in retail and e-commerce. The customer success and product expansion has attracted the interest of investors. Starburst has raised a total of $414 million, including a recent $250 million series D funding round that gave the company a $3.35 billion valuation. Investor enthusiasm has been driven by Starburst’s value proposition which is accelerating the analysis of data wherever it resides across an organization — including data lakes, data warehouses, relational and non-relational databases — on-premises, in the cloud or across a hybrid environment. The focus on enabling the processing and analysis of distributed data is well-aligned with the concept of the data mesh and Starburst has taken steps to strengthen this association with the recent introduction of functionality to support the management and sharing of data as a product. This is a key principle of data mesh, the ability of a business domain to make data available for self-serve consumption and analysis by other business domains across an organization.
Starburst was founded in 2017 to build a commercial business around the Trino distributed SQL query engine (formerly known as PrestoSQL). The company was originally focused on supporting customers using Trino to perform SQL-based data analysis in Apache Hadoop and object storage environments. The latter has been a significant growth engine, with more than one-half (53%) of participants in Ventana Research’s Analytics and Data Benchmark Research currently using object stores in their analytics efforts and an additional 18% planning to do so. Additionally, Starburst has built a range of functionality around Trino to create a broader data consumption layer, with capabilities for data access, data management, advanced analytics, security and hybrid- and multi-cloud connectivity. The company has grown rapidly and now has a roster of customers including FINRA and DBS Bank in financial services, Assurance in insurance, Emis in healthcare, and Zalando, Carrefour, DoorDash, and GrubHub in retail and e-commerce. The customer success and product expansion has attracted the interest of investors. Starburst has raised a total of $414 million, including a recent $250 million series D funding round that gave the company a $3.35 billion valuation. Investor enthusiasm has been driven by Starburst’s value proposition which is accelerating the analysis of data wherever it resides across an organization — including data lakes, data warehouses, relational and non-relational databases — on-premises, in the cloud or across a hybrid environment. The focus on enabling the processing and analysis of distributed data is well-aligned with the concept of the data mesh and Starburst has taken steps to strengthen this association with the recent introduction of functionality to support the management and sharing of data as a product. This is a key principle of data mesh, the ability of a business domain to make data available for self-serve consumption and analysis by other business domains across an organization.
 The Trino distributed SQL query engine remains at the heart of Starburst’s ability to accelerate the analysis of data across an organization. Trino is a fork of the Presto project, which was originally created at Facebook in 2012 by Martin Traverso, Dain Sundstrom, David Phillips, and Eric Hwang, all of whom are now employees of Starburst. It is an open-source parallel query engine that enables organizations to use their preferred SQL analysis tools to query data in object storage, Apache Hadoop and relational and non-relational databases. Trino also supports caching for frequently accessed data and SQL pushdown to the source data platform, as well as query federation capabilities to access data from multiple repositories with a single query. Starburst Enterprise is a commercially supported distribution of Trino for deployment on-premises or in the cloud, while the company also provides the Starburst Galaxy managed service. Both offer additional connectivity, security and data-management functionality. Multi-cloud and hybrid environments are supported by Starburst Stargate which offers a gateway to link data catalogs and data sources between Starburst clusters, providing access to data without the need to move it to a single location. This is a growing concern as compute and storage are distributed across a hybrid and multi-cloud architecture. I assert that by 2025, more than three-quarters of enterprises will have data spread across multiple cloud providers and on-premises data centers, requiring investment in data-management products that span multiple locations. Key drivers include safeguarding data for data sovereignty, business continuity and performance.
The Trino distributed SQL query engine remains at the heart of Starburst’s ability to accelerate the analysis of data across an organization. Trino is a fork of the Presto project, which was originally created at Facebook in 2012 by Martin Traverso, Dain Sundstrom, David Phillips, and Eric Hwang, all of whom are now employees of Starburst. It is an open-source parallel query engine that enables organizations to use their preferred SQL analysis tools to query data in object storage, Apache Hadoop and relational and non-relational databases. Trino also supports caching for frequently accessed data and SQL pushdown to the source data platform, as well as query federation capabilities to access data from multiple repositories with a single query. Starburst Enterprise is a commercially supported distribution of Trino for deployment on-premises or in the cloud, while the company also provides the Starburst Galaxy managed service. Both offer additional connectivity, security and data-management functionality. Multi-cloud and hybrid environments are supported by Starburst Stargate which offers a gateway to link data catalogs and data sources between Starburst clusters, providing access to data without the need to move it to a single location. This is a growing concern as compute and storage are distributed across a hybrid and multi-cloud architecture. I assert that by 2025, more than three-quarters of enterprises will have data spread across multiple cloud providers and on-premises data centers, requiring investment in data-management products that span multiple locations. Key drivers include safeguarding data for data sovereignty, business continuity and performance.
 The fact that Trino accelerates analysis of data in object storage and Apache Hadoop means that Starburst is closely associated with data lakes. This functionality also has a key role to play in the evolution of the data lake into what we have described as hydroanalytic data platforms. However, Trino’s query federation capabilities, combined with Stargate, illustrate Starburst’s relevance to data mesh. This was reinforced by the introduction of Starburst Data Products which provides an environment for data producers to define curated datasets as well as the relevant metadata that allows data consumers to discover and access them. Access is enabled by Starburst’s access control and security capabilities, while analysis of the data products is performed by the distributed SQL query engine functionality.
The fact that Trino accelerates analysis of data in object storage and Apache Hadoop means that Starburst is closely associated with data lakes. This functionality also has a key role to play in the evolution of the data lake into what we have described as hydroanalytic data platforms. However, Trino’s query federation capabilities, combined with Stargate, illustrate Starburst’s relevance to data mesh. This was reinforced by the introduction of Starburst Data Products which provides an environment for data producers to define curated datasets as well as the relevant metadata that allows data consumers to discover and access them. Access is enabled by Starburst’s access control and security capabilities, while analysis of the data products is performed by the distributed SQL query engine functionality.
Adoption of the data mesh concept is in its very early stages, and for some organizations it will involve considerable cultural and organizational changes, as well as the adoption of technologies that enable distributed data processing, access and governance. While Starburst Data Products is designed to strengthen the association with data mesh, it can also provide value in enabling governed data sharing and access even if an organization is not investing in the cultural and organizational changes that will be required to implement data mesh. Data lake adoption is more widespread and is likely to continue to drive most interest in Starburst for some time to come. I recommend that organizations looking to generate greater value from their data lake investments and enable hybrid and multi-cloud data processing examine Starburst’s product portfolio and also consider the potential role of data lake infrastructure in distributed data processing.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








