
I have previously written about the functional evolution and emerging use cases for NoSQL databases, a category of non-relational databases that first emerged 15 or so years ago and are now well established as potential alternatives to relational databases. NoSQL is a term that is used to describe a variety of databases that fall into four primary functional categories: key-value stores, wide column stores, document-oriented databases and graph databases. Each is worthy of further exploration, which is why I am examining them over a series of analyst perspectives, starting with graph databases.
Today, graph databases are seen as a subset of the NoSQL category. However, the underlying principles predate the relational database model, which has dominated the operational and analytic data platform sectors for the past 50 years. Graph structures were used to represent and navigate data in network and hierarchical data models in the 1960s, while graph theory — the mathematical approach of modeling relationships between entities — can be traced back to Leonhard Euler’s Seven Bridges of Königsberg paper, published in 1736. This was more than 100 years before the emergence of set theory, which forms the basis of the relational data model.
Spend any time with proponents of graph databases and they will tell you that the graph data model and graph databases are inherently more suitable than relational databases for a range of use cases, despite the fact that the relational model has dominated the database market since the 1970s. The reason for this is that relational databases store data as entities and attributes in tables of rows and columns. A combination of normalization, row and column keys and joins between tables is required to identify relationships between entities and attributes in a relational database.
In comparison, graph databases natively store not only the entities and attributes, but also the relationships. Proponents of graph databases argue that the native storage of relationships means that graph databases are intrinsically more efficient than relational databases for applications and use cases that depend on identifying and navigating the connections between entities. Use cases that take advantage of the graph model include navigation systems, social media and fraud detection as well as content and knowledge management based on semantic models. Other potential applications include network management, asset management, customer experience management, recommendation engines, security and threat detection, master data management and supply chain management.
Despite the arguments in favor of graph databases, adoption has been relatively limited. Fewer than 1 in 6 participants in Ventana Research’s Analytics and Data Benchmark Research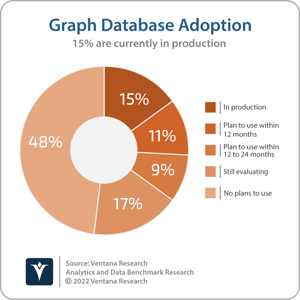 (15%) are in production with graph databases today, with 11% planning to use them within 12 months, and another 9% within two years. In comparison, 89% of participants are in production with or plan to use relational databases. There are several reasons behind the relative scarcity of graph databases in production. Initial adoption of graph databases was reliant on developers and data teams understanding that they had a problem or opportunity that was suitable for the graph data model. As such, graph database vendors spent a lot of initial energy and marketing dollars evangelizing the potential benefits of the graph data model compared to the relational model.
(15%) are in production with graph databases today, with 11% planning to use them within 12 months, and another 9% within two years. In comparison, 89% of participants are in production with or plan to use relational databases. There are several reasons behind the relative scarcity of graph databases in production. Initial adoption of graph databases was reliant on developers and data teams understanding that they had a problem or opportunity that was suitable for the graph data model. As such, graph database vendors spent a lot of initial energy and marketing dollars evangelizing the potential benefits of the graph data model compared to the relational model.
The dominance of relational databases has also posed a challenge to graph databases, thanks to the development of graph compute engines that enable and accelerate graph analysis of data in a relational database. Graph compute engines and relational databases may not be as efficient for supporting operational applications that rely on the identification and navigation of relationships, but they do provide a potential alternative for applications that rely on executing graph queries. This is especially so for organizations that already store data in a relational database and lack the skills or knowledge required for graph databases. In addition to investing in sales and marketing to improve knowledge about graph databases, vendors have recently taken steps to better address the needs of developers who are increasingly important in selecting databases to support the development of new applications. To accelerate adoption of new application development projects, graph database vendors have invested in graphical user interfaces to facilitate graph data model design, graph exploration and interactive analytics as well as cloud managed services to lower the barriers to adoption by removing requirements for upfront investment in related infrastructure.
Data scientists have also become a primary focal point for graph databases. The native representation of relationships in graph databases can be significant in surfacing features for use in machine-learning modeling. Traditional approaches have seen data scientists extract these features into specialist data platforms to support the development and training of machine-learning models before deploying the models into graph databases for operational inferencing. There has been a concerted effort in recent years by graph database providers to enable data scientists to develop and train a machine-learning model in the graph database, rather than extracting it into a separate environment, with graph database providers delivering support for data science algorithms and frameworks.
The combination of these efforts can be expected to result in increased adoption of graph databases. I assert that by 2026, more than one-quarter of organizations will adopt graph databases to support applications that rely on the identification and navigation of relationships. In addition, another significant barrier to more widespread adoption of graph databases could be about to fall. There are two primary models for graph databases: the labelled-property graph model and the Resource Description Framework model. RDF — along with its query language, SPARQL — is a standard of the World Wide Web Consortium. There is no such standard for the labelled-property graph model, and the lack of a standard query language has arguably been a challenge for potential adopters, forcing them to learn and use new languages tied to specific implementations. Graph Query Language is a proposed standard language for querying property graphs being developed as a project overseen by a joint technical committee of the International Organization for Standardization and the International Electrotechnical Commission. GQL draws on multiple existing declarative database query languages for property graphs, including Cypher (originally developed by Neo4j), GSQL (originally developed by TigerGraph), property graph query language (originally developed by Oracle) and G-CORE (originally developed by the Linked Data Benchmark Council).
databases to support applications that rely on the identification and navigation of relationships. In addition, another significant barrier to more widespread adoption of graph databases could be about to fall. There are two primary models for graph databases: the labelled-property graph model and the Resource Description Framework model. RDF — along with its query language, SPARQL — is a standard of the World Wide Web Consortium. There is no such standard for the labelled-property graph model, and the lack of a standard query language has arguably been a challenge for potential adopters, forcing them to learn and use new languages tied to specific implementations. Graph Query Language is a proposed standard language for querying property graphs being developed as a project overseen by a joint technical committee of the International Organization for Standardization and the International Electrotechnical Commission. GQL draws on multiple existing declarative database query languages for property graphs, including Cypher (originally developed by Neo4j), GSQL (originally developed by TigerGraph), property graph query language (originally developed by Oracle) and G-CORE (originally developed by the Linked Data Benchmark Council).
It is anticipated that GQL could be approved as a standard in 2024. In the interim, multiple property graph vendors and open-source projects have committed to adoption of GQL, and vendor engagement in the standardization process means that organizations can more comfortably proceed with property graph database adoption in the interim. Graph databases are not suitable for every data platform use case, but there are multiple applications for which graph databases can improve the ability for organizations to deliver customer service and operational efficiency improvements. I recommend that organizations should at least become acquainted with graph databases and the use cases that graph databases are applicable for, with a view to improving the development and efficiency of applications that rely on the identification and navigation of relationships.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








