

As businesses become more data-driven, they are increasingly dependent on the quality of their data and the reliability of their data pipelines. Making decisions based on data does not guarantee success, especially if the business cannot ensure that the data is accurate and trustworthy. While there is potential value in capturing all data — good or bad — making decisions based on low-quality data may do more harm than good.
I recently described the emerging market for data observability software, describing how a slew of new vendors have sprung up with offerings designed to automate the task of monitoring data quality and reliability. As I explained, these data observability offerings are inspired by the success of observability platforms that provide an environment for monitoring metrics, traces and logs to track application and infrastructure performance. They are focused on data workloads, specifically ensuring that data meets quality and reliability requirements used for analytics and governance projects. One of the most prominent vendors to emerge in the data observability space is Bigeye.
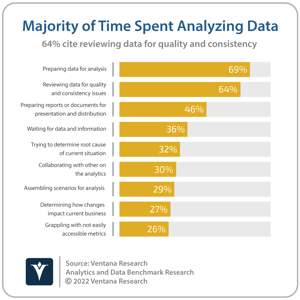
The company was founded in late 2018 by Chief Executive Officer Kyle Kirwan and Chief Technology Officer Egor Gryaznov, both former employees of Uber, where Kirwan led the development of Uber’s Databook internal data catalog, amongst other things. Through their experience with various data-related projects at Uber, Bigeye’s founders identified reliability as a key concern that impacted the success of data projects for which organizations were largely reliant on data-quality tools that were dependent on the manual efforts of data engineers, data architects, data scientists and data analysts. As a result, many data teams were not as productive as they might be, with time and effort spent on manually troubleshooting data-quality issues and testing data pipelines. Additionally, while available tools enabled data teams to respond to quality issues, they did not provide a way to identify quality thresholds or measure improvement, making it difficult to demonstrate to the business the value of time spent rectifying data-quality problems. Ventana Research’s Analytics and Data Benchmark Research indicates that this issue impacts many organizations, with almost two-thirds (64%) of respondents reporting that reviewing data for quality and consistency issues is one of the most time-consuming aspects of analyzing data.
 Bigeye offers a hosted data-observability platform that is designed to meet those challenges with functionality that addresses data-quality monitoring, alerts and automated resolution. Automation is a critical aspect of data operations (DataOps), which encapsulates new approaches to data management driven by automated data monitoring and the continuous delivery of data into operational and analytical processes. DataOps, and data observability in particular, is increasingly important to data engineers as a means of reducing the manual overhead involved in managing data pipelines and maintaining data quality, as well as providing statistical evidence of the value of their efforts.
Bigeye offers a hosted data-observability platform that is designed to meet those challenges with functionality that addresses data-quality monitoring, alerts and automated resolution. Automation is a critical aspect of data operations (DataOps), which encapsulates new approaches to data management driven by automated data monitoring and the continuous delivery of data into operational and analytical processes. DataOps, and data observability in particular, is increasingly important to data engineers as a means of reducing the manual overhead involved in managing data pipelines and maintaining data quality, as well as providing statistical evidence of the value of their efforts.
We assert that through 2025, data observability will continue to be a priority for the evolution of DataOps products as vendors deliver more automated approaches to data engineering, improving trust in enterprise data. The ability to monitor and measure improvements in data quality relies on instrumentation, which is handled by Bigeye’s data observability platform in the form of what it calls “autometrics.” Once connected via a read-only JDBC connection to a data source — such as a database, data warehouse or query engine — Bigeye creates a sample of the dataset and automatically recommends data-quality metrics with which to track the health of the dataset. Metrics include freshness, cardinality, distribution, syntax and volume, as well as the existence of nulls and blanks. Having tracked the associated data for 5-10 days, Bigeye automatically creates forecasting models with upper and lower thresholds for each relevant metric. As, and when, these thresholds are breached, Bigeye automatically alerts groups or individuals through their preferred channel, including email, PagerDuty, Slack or Webhooks.
-png.png?width=300&name=VR_2022_Data_Operations_Assertion_4_Square%20(1)-png.png) In late 2021, the company also added new capabilities called Deltas, Issues, and Dashboard, to round out its data-quality workflow. First came Deltas, launched in November, which is designed to automatically map and compare multiple versions of a data set, identifying schema differences and missing data. Deltas can be used when replicating data from a source operational database to an analytic data warehouse; to migrate data between data centers and clouds; and prior to promoting data from staging to production. Issues and Dashboard followed in December, with Issues providing an interface for aggregating related alerts to facilitate faster resolution. Metadata from the resolution of Issues fuels Dashboard, which provides a higher level “command center” view of Issues, datasets and service-level agreements, as well as higher level monitoring to track overall team progress in maintaining and improving data quality.
In late 2021, the company also added new capabilities called Deltas, Issues, and Dashboard, to round out its data-quality workflow. First came Deltas, launched in November, which is designed to automatically map and compare multiple versions of a data set, identifying schema differences and missing data. Deltas can be used when replicating data from a source operational database to an analytic data warehouse; to migrate data between data centers and clouds; and prior to promoting data from staging to production. Issues and Dashboard followed in December, with Issues providing an interface for aggregating related alerts to facilitate faster resolution. Metadata from the resolution of Issues fuels Dashboard, which provides a higher level “command center” view of Issues, datasets and service-level agreements, as well as higher level monitoring to track overall team progress in maintaining and improving data quality.
Data observability is a relatively new approach to tackling an age-old problem, but one that is likely to become increasingly critical to businesses as they become more data-driven and invest in DataOps approaches that automate previously manual data-operations processes. I recommend that organizations exploring potential approaches to improving data reliability should examine the emerging breed of new data observability providers, including Bigeye, to understand how they can facilitate greater trust in data and accelerate data-driven business decisions.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








