
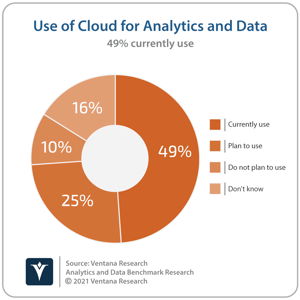
Few trends have had a bigger impact on the data platforms landscape than the emergence of cloud computing. The adoption of cloud computing infrastructure as an alternative to on-premises datacenters has resulted in significant workloads being migrated to the cloud, displacing traditional server and storage vendors. Almost one-half (49%) of respondents to Ventana Research’s Analytics and Data Benchmark Research currently use cloud computing products for analytics and data, and a further one-quarter plan to do so. In addition to deploying data workloads on cloud infrastructure, many organizations have also adopted cloud data and analytics services offered by the same cloud providers, displacing traditional data platform vendors. Organizations now have greater choice in relation to potential products and providers for data and analytics workloads, but also need to think about integrating services offered by cloud providers with established technology and processes. Having pioneered the concept, Amazon Web Services has arguably benefitted more than most from adoption of cloud computing, and is also in the process of expanding and adjusting its portfolio to alleviate challenges and encourage even greater adoption.
 What we now know as Amazon Web Services was initially created to support the ecommerce requirements of Amazon.com. The organization officially made its debut in 2006 with the launch of Amazon Simple Storage Service, which was followed later the same year by Amazon Simple Queue Service and Amazon Elastic Compute Cloud. It wasn’t until more than a year later that the fledgling AWS began to expand on this initial portfolio, but the trickle of new launches over subsequent years quickly turned into a flood. AWS today offers more than 200 cloud services from datacenters providing 84 availability zones in 26 regions around the globe. The importance of data in the AWS portfolio is highlighted by the fact that the fourth service launched by the company, in late 2007, was the Amazon SimpleDB database. AWS’s approach to data and analytics could be described as “the more, the better.” Today, AWS has 11 different databases in its cloud databases portfolio, including the Amazon RDS, Amazon Aurora and Amazon Redshift relational databases as well as the Amazon DynamoDB, Amazon DocumentDB, Amazon KeySpaces and Amazon Neptune NoSQL databases. AWS also offers numerous data processing, data management, analytics and machine learning services that fall under its data lakes and analytics portfolio, including the Amazon Athena query service, Amazon Glue for data preparation and loading, Amazon Kinesis for streaming data analytics, and Amazon QuickSight for business intelligence (featured in the 2021 Ventana Research Value Index for Analytics and Data). As a result, organizations could theoretically address the majority of — if not all — data and analytics requirements using only AWS cloud services. In reality, AWS services co-exist with a combination of on-premises software and cloud services delivered by a variety of vendors. For example, more than two-fifths (42%) of those using cloud computing for analytics and data are currently using more than one cloud provider, according to Ventana Research’s Analytics and Data Benchmark Research.
What we now know as Amazon Web Services was initially created to support the ecommerce requirements of Amazon.com. The organization officially made its debut in 2006 with the launch of Amazon Simple Storage Service, which was followed later the same year by Amazon Simple Queue Service and Amazon Elastic Compute Cloud. It wasn’t until more than a year later that the fledgling AWS began to expand on this initial portfolio, but the trickle of new launches over subsequent years quickly turned into a flood. AWS today offers more than 200 cloud services from datacenters providing 84 availability zones in 26 regions around the globe. The importance of data in the AWS portfolio is highlighted by the fact that the fourth service launched by the company, in late 2007, was the Amazon SimpleDB database. AWS’s approach to data and analytics could be described as “the more, the better.” Today, AWS has 11 different databases in its cloud databases portfolio, including the Amazon RDS, Amazon Aurora and Amazon Redshift relational databases as well as the Amazon DynamoDB, Amazon DocumentDB, Amazon KeySpaces and Amazon Neptune NoSQL databases. AWS also offers numerous data processing, data management, analytics and machine learning services that fall under its data lakes and analytics portfolio, including the Amazon Athena query service, Amazon Glue for data preparation and loading, Amazon Kinesis for streaming data analytics, and Amazon QuickSight for business intelligence (featured in the 2021 Ventana Research Value Index for Analytics and Data). As a result, organizations could theoretically address the majority of — if not all — data and analytics requirements using only AWS cloud services. In reality, AWS services co-exist with a combination of on-premises software and cloud services delivered by a variety of vendors. For example, more than two-fifths (42%) of those using cloud computing for analytics and data are currently using more than one cloud provider, according to Ventana Research’s Analytics and Data Benchmark Research.
As its role as a technology provider becomes increasingly strategic, AWS is responding by expanding its services to increase adoption. This is being done in a variety of ways, but recent announcements at the company’s re:Invent technology event highlighted three key initiatives: lowering barriers to adoption for new workloads, lowering barriers to migration of existing workloads, and increasing maturity of functionality. Cloud services alleviate some of the core challenges of infrastructure provisioning, configuration and management, but users remain responsible for configuring and managing the software that runs on those cloud services. Serverless data processing enables users to enjoy the benefits of data processing without the concern of software provisioning, configuration, maintenance and scaling. At re:Invent, AWS previewed four new serverless data services, launching Amazon Redshift Serverless (data warehousing), Amazon EMR Serverless (big data processing), Amazon MSK Serverless (Apache Kafka messaging and events), and Amazon Kinesis Data Streams On-Demand (streaming data). All four services are designed to lower the barriers to adoption, while delivering pay-per-use consumption.
-1.png?width=300&name=VR_2022_Data_Assertion_9_Square%20(2)-1.png) AWS Database Migration Service has a key role to play in lowering barriers to data workload migration by helping customers migrate existing database workloads from on-premises datacenters to the cloud. This is a trend that is set to continue. We assert that through 2025, 7 in ten organizations will migrate on-premises workloads to cloud data platforms, shifting focus to solving business needs rather than maintaining systems. At re:Invent, AWS introduced DMS Fleet Advisor, a new offering that is designed to automate the discovery and inventory of an organization’s database estate, and also enables users to build customized migration plans. DMS Fleet Advisor is available via the new AWS DMS Studio, a console user interface for managing database migrations, including inventory and discovery, schema conversion and data migration. Accelerated adoption is also enabled by helping customers better understand how and when to combine services to address specific use-cases. A prime example is Data Lake House, which details multiple services addressing data storage, data integration, data governance, data processing, streaming data, data warehousing and analytics. An important component of the Data Lake House approach on AWS is AWS Lake Formation, which enables the configuration and management of a data lake on Amazon S3. At re:Invent, AWS announced support for Governed Tables in Lake Formation, which are designed to manage conflicts and errors and provide consistency as data is updated or changed. This is a prime example of the trend we recently described where structured data processing is added to data lakes to turn them into hydroanalytic data platforms. Similarly, AWS also announced the public preview of Amazon Athena ACID transactions, leveraging the Apache Iceberg table format to support the consistent updating and deletion of data in the Amazon Athena interactive query service for analyzing data in S3.
AWS Database Migration Service has a key role to play in lowering barriers to data workload migration by helping customers migrate existing database workloads from on-premises datacenters to the cloud. This is a trend that is set to continue. We assert that through 2025, 7 in ten organizations will migrate on-premises workloads to cloud data platforms, shifting focus to solving business needs rather than maintaining systems. At re:Invent, AWS introduced DMS Fleet Advisor, a new offering that is designed to automate the discovery and inventory of an organization’s database estate, and also enables users to build customized migration plans. DMS Fleet Advisor is available via the new AWS DMS Studio, a console user interface for managing database migrations, including inventory and discovery, schema conversion and data migration. Accelerated adoption is also enabled by helping customers better understand how and when to combine services to address specific use-cases. A prime example is Data Lake House, which details multiple services addressing data storage, data integration, data governance, data processing, streaming data, data warehousing and analytics. An important component of the Data Lake House approach on AWS is AWS Lake Formation, which enables the configuration and management of a data lake on Amazon S3. At re:Invent, AWS announced support for Governed Tables in Lake Formation, which are designed to manage conflicts and errors and provide consistency as data is updated or changed. This is a prime example of the trend we recently described where structured data processing is added to data lakes to turn them into hydroanalytic data platforms. Similarly, AWS also announced the public preview of Amazon Athena ACID transactions, leveraging the Apache Iceberg table format to support the consistent updating and deletion of data in the Amazon Athena interactive query service for analyzing data in S3.
AWS is not alone in building out its data infrastructure services. Key cloud rivals Google Cloud and Microsoft Azure also continue to do so, while other existing data providers such as Oracle and Teradata are also operating in AWS as well as other clouds. Enterprises looking to adopt cloud-based data processing and analytics face a disorienting array of data storage, data processing, data management and analytics offerings that need to be examined in the context of adaptability, manageability and reliability as well as functional capabilities. Customer experience throughout the life cycle of engagement with a vendor, and the total cost of ownership and return on investment required to operate a data platform are also critical considerations.
There is no doubt that cloud computing will continue to have a significant impact on the data sector in the years to come as future enterprise IT architecture will span multiple cloud providers as well as on-premises datacenters. The question is no longer if data workloads will be deployed in the cloud, but which data workloads will be deployed in the cloud, and when. Organizations need to evaluate potential workload placement options in the context of larger technology and business strategies and have a wide variety of potential providers. Given the depth of its cloud expertise and the breadth of its data services, I recommend that organizations evaluate Amazon Web Services when considering potential data cloud services providers.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








