
It is well known that data integration, transformation and preparation represent a significant proportion of the time and effort required in any analytics project. Traditionally, operational data platforms are designed to store, manage, and process data to support worker-, customer- and partner-facing operational applications, and data is then extracted, transformed, and loaded (or “ETLed”) into a separate analytic data platform, which is designed to store, manage, process, and analyze data. More than two-thirds (69%) of participants in Ventana Research’s Analytics and Data Benchmark Research cite preparing data for analysis as the most time-consuming aspect of the analytics process. Reducing the time and effort spent on data integration and preparation can significantly accelerate time to business insight. In that context, it is no surprise the concept of zero-ETL integration has generated a lot of interest among enterprises in recent years.
As highlighted by the 2023 Ventana Research Buyers Guide for Data Pipelines, the development, testing and deployment of data pipelines is essential to generating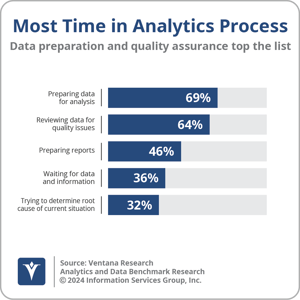 intelligence from data. I previously described how batch ETL pipelines, in which data is extracted from its source operational database and transformed in a dedicated staging area before being loaded into a target analytic database, are unsuitable for data-driven processes that require more agile, continuous data processing. A variety of approaches are promoted by data management vendors to accelerate data integration and transformation processes. ETL pipelines can be automated and orchestrated to reduce manual intervention, while extract, load and transform (ELT) pipelines involve the use of a more lightweight staging tier and utilize the data processing functionality and processing power of the target data platform to transform the data after it has been loaded. ETL and ELT pipelines can both be accelerated by using change data capture (CDC), which identifies and tracks changes to the source database and only synchronizes changed data, rather than the entire dataset. Zero-ETL has emerged as an alternative in recent years, with proponents arguing that it enables data to be replicated from the source operational database and immediately available for analysis in the target analytic database. The term zero-ETL, along with some of the marketing around it, implies that users can do away with extraction, transformation and loading of data entirely. That might sound too good to be true, and in many cases it will be. While zero-ETL automates extraction and loading, there may still be transformation requirements, depending on the specific use case.
intelligence from data. I previously described how batch ETL pipelines, in which data is extracted from its source operational database and transformed in a dedicated staging area before being loaded into a target analytic database, are unsuitable for data-driven processes that require more agile, continuous data processing. A variety of approaches are promoted by data management vendors to accelerate data integration and transformation processes. ETL pipelines can be automated and orchestrated to reduce manual intervention, while extract, load and transform (ELT) pipelines involve the use of a more lightweight staging tier and utilize the data processing functionality and processing power of the target data platform to transform the data after it has been loaded. ETL and ELT pipelines can both be accelerated by using change data capture (CDC), which identifies and tracks changes to the source database and only synchronizes changed data, rather than the entire dataset. Zero-ETL has emerged as an alternative in recent years, with proponents arguing that it enables data to be replicated from the source operational database and immediately available for analysis in the target analytic database. The term zero-ETL, along with some of the marketing around it, implies that users can do away with extraction, transformation and loading of data entirely. That might sound too good to be true, and in many cases it will be. While zero-ETL automates extraction and loading, there may still be transformation requirements, depending on the specific use case.
The claim is that zero-ETL makes operational data available instantly for real-time analytics, which could be useful for including artificial intelligence and machine learning (AI/ML) inferencing to support intelligent operational applications. Removing the need for data transformation can only be met if all the data required for an analytics project is generated by a single source, however. Many analytics projects rely on combining data from multiple applications. If this is the case, then transformation of the data will be required after loading to integrate and prepare it for analysis. Even if all the data is generated by a single application, the theory that data does not need to be transformed relies on the assumption that schema is strictly enforced when the data is generated. If not, enterprises are likely to find that they need to use declarative transformations to cleanse and normalize the data for longer-term analytics or data governance requirements. As such, zero-ETL could arguably be seen as a form of ELT that automates extraction and loading and has the potential to remove the need for transformation in some use cases. ELT is rising in popularity. I assert that by 2026, more than three-quarters of enterprises’ information architectures will support ELT patterns to accelerate data processing and maximize the value of large volumes of data.
inferencing to support intelligent operational applications. Removing the need for data transformation can only be met if all the data required for an analytics project is generated by a single source, however. Many analytics projects rely on combining data from multiple applications. If this is the case, then transformation of the data will be required after loading to integrate and prepare it for analysis. Even if all the data is generated by a single application, the theory that data does not need to be transformed relies on the assumption that schema is strictly enforced when the data is generated. If not, enterprises are likely to find that they need to use declarative transformations to cleanse and normalize the data for longer-term analytics or data governance requirements. As such, zero-ETL could arguably be seen as a form of ELT that automates extraction and loading and has the potential to remove the need for transformation in some use cases. ELT is rising in popularity. I assert that by 2026, more than three-quarters of enterprises’ information architectures will support ELT patterns to accelerate data processing and maximize the value of large volumes of data.
Enterprises concerned about vendor lock-in should also be aware that zero-ETL offerings introduced to date only provide for point-to-point integration between specific data platforms that cannot be replicated with alternative databases. The concept of zero-ETL integration was popularized by Amazon Web Services, which introduced continuous replication of data between its Amazon Aurora MySQL operational database and its Amazon Redshift analytic database at its re:Invent customer event in 2022. The company then followed that up at re:Invent 2023 when it announced zero-ETL integration to Amazon Redshift from Amazon Aurora PostgreSQL, Amazon DynamoDB, and Amazon RDS for MySQL, as well as zero-ETL integration between Amazon DynamoDB and Amazon OpenSearch Service. Other vendors that have embraced zero-ETL include Salesforce, which introduced zero-ETL integration between Salesforce Data Cloud and Snowflake and Databricks in September 2023, while the introduction of Couchbase Capella columnar service promised zero-ETL integration between operational and analytic nodes. Additionally, Google described the ability to federate queries to Google Cloud Bigtable and from Google Cloud BigQuery as zero-ETL. Many other vendors offer products that automatically replicate data from source to target without the need for up-front transformation or enable virtual or federated queries to be performed on data in external data platforms. Given the level of interest in zero-ETL and the industry’s love of buzzwords, we expect many of these to be rebranded as providing zero-ETL integration.
Any technology that reduces the time and effort spent on data integration and preparation can accelerate time to business value from analytic projects. The implied advantages of zero-ETL make it an attractive proposition for accelerating real-time analytics on operational data in support of intelligent operational applications. I recommend that enterprises include zero-ETL capabilities in their evaluations, while also being aware that there are significant limitations of the approach that make it unsuitable for other use cases with broader analytics, data management and data governance requirements.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








