
I have previously written about growing interest in the data lakehouse as one of the design patterns for delivering hydroanalytics analysis of data in a data lake. Many organizations have invested in data lakes as a relatively inexpensive way of storing large volumes of data from multiple enterprise applications and workloads, especially semi- and unstructured data that is unsuitable for storing and processing in a data warehouse. However, early data lake projects lacked structured data management and processing functionality to support multiple business intelligence efforts as well as data science and even operational applications.
The lakehouse concept being pioneered by several vendors, including Databricks, is designed to bring the best of data lakes and data warehousing together by incorporating data warehousing functionality into the data lake. We see growing interest in the approach, especially among organizations that have already made an investment in the underlying data lake functionality. I assert that by 2024, more than three-quarters of current data lake adopters will invest in data lakehouse technologies to improve the business value generated from the accumulated data.
functionality into the data lake. We see growing interest in the approach, especially among organizations that have already made an investment in the underlying data lake functionality. I assert that by 2024, more than three-quarters of current data lake adopters will invest in data lakehouse technologies to improve the business value generated from the accumulated data.
Databricks was established in 2013 by the founders of the Apache Spark open source distributed data processing framework. The company created a cloud managed service built around Apache Spark as well as various other open source projects, including TensorFlow, MLflow and PyTorch. Initially, it targeted data engineers, data scientists and developers for big data and machine-learning workloads. In recent years, Databricks has added support for more traditional data warehousing and business intelligence workloads as well as data governance capabilities, with the platform also offering functionality targeted at data analysts and data management professionals.
In 2019, the company launched the open source Delta Lake table storage project, followed in 2020 by the launch of the Delta Engine high-performance query engine (built on its Photon native vectorized execution engine). The 2020 acquisition of Redash provided open source dashboarding and visualization functionality that is the basis of the Databricks SQL serverless data warehouse. 2020 also saw the company brand its combination of offerings as a data lakehouse, and in 2021 it added another important component of the Data Lakehouse Platform, Unity Catalog, which provides unified governance for files, tables, dashboards and machine learning models.
Databricks’ Data Lakehouse Platform is available on Amazon Web Services, Google Cloud and Microsoft Azure (as Azure Databricks), and has more than 7,000 customers. The company remains private but is likely to be heading for an initial public offering in the next few years if economic conditions are right. It has raised $3.5 billion in funding; the latest $1.6 billion series H round announced in August 2021 valued the company at $38 billion.
Adoption of Apache Spark is driven by its combination of high-performance, in-memory processing and versatility. The data processing engine can be used for data engineering, data science and machine learning workloads involving structured and unstructured data. Using both batch and stream processing and the user’s preferred language from a choice of Python, SQL, Scala, Java and R. Databricks combines this versatility with a cloud-based managed service approach via its Data Lakehouse Platform service, mixing and matching the various underlying components to deliver functionality aimed at different personas: data science and engineering, machine learning or SQL.
At the heart of the Data Lakehouse Platform is Databricks Runtime, which combines Apache Spark with Delta Lake (amongst other things). The Databricks Data Science & Engineering environment is built on Databricks Runtime and enables collaboration among data scientists, data engineers and data analysts. It also forms the basis of the Databricks Machine Learning environment, which adds machine learning libraries including TensorFlow, PyTorch, Keras and XGBoost as well as AutoML, feature store and MLOps capabilities.
The combination of Delta Lake and Unity Catalog provides the foundation of Databricks’ Lakehouse functionality. Unity Catalog delivers data governance, data sharing and data auditing, with data lineage added in June. Delta Lake delivers functionality to create tables that support atomic, consistent, isolated and durable transactions, as well as updates and deletes, metadata handling and schema enforcement.
We are seeing increased interest in transaction management for data lakes. The results of Ventana Research’s Data Lakes Dynamics Insights research showed that more than one-half of organizations 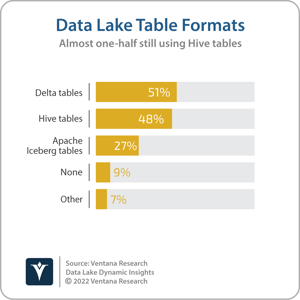 with a data lake are using at least one emerging transaction management protocol (Apache Hudi, Apache Iceberg or Delta Lake), with 51% using Delta tables today. June also saw Databricks announce query federation capabilities to analyze data in external sources such as PostgreSQL, MySQL and AWS Redshift as well as the general availability of its Photon native vectorized execution engine on Databricks Workspaces. The latter is Databricks’ primary user interface, providing access to notebooks, libraries, experiments, queries and dashboards, depending on whether the user is focused on data science and engineering, machine learning or SQL-based analysis.
with a data lake are using at least one emerging transaction management protocol (Apache Hudi, Apache Iceberg or Delta Lake), with 51% using Delta tables today. June also saw Databricks announce query federation capabilities to analyze data in external sources such as PostgreSQL, MySQL and AWS Redshift as well as the general availability of its Photon native vectorized execution engine on Databricks Workspaces. The latter is Databricks’ primary user interface, providing access to notebooks, libraries, experiments, queries and dashboards, depending on whether the user is focused on data science and engineering, machine learning or SQL-based analysis.
For data governance professionals, Databricks Data Explorer provides a user interface for many Unity Catalog features, including functionality for search and discovery as well as managing data ownership and access permissions. In addition to targeting functionality at users based on their role, Databricks is also targeting customers for Databricks Data Lakehouse based on industry. Although the platform can be used by organizations in any sector, Databricks has launched industry-focused offerings targeting retail and consumer goods, healthcare and life sciences, financial services and media and entertainment. The offerings include Databricks Data Lakehouse along with use case accelerators and Brickbuilder Solutions developed with consulting and systems integration partners, and are supported by the company’s industry-focused sales and support organizations.
Databricks is now well-established as an analytic data platform provider for data science and machine learning workloads. Although it is less well-known for data warehousing and business intelligence workloads, the company has made significant progress in recent years, thanks to its investments in Databricks SQL and Delta Lake, and its overall promotion of the data lakehouse concept. I recommend that organizations investing in updates of analytic data platforms for data warehousing and/or data science include Databricks in the evaluations.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








