

Ventana Research’s Data Lakes Dynamics Insights research illustrates that while data lakes are fulfilling their promise of enabling organizations to economically store and process large volumes of raw data, data lake environments continue to evolve. Data lakes were initially based primarily on Apache Hadoop deployed on-premises but are now increasingly based on cloud object storage. Adopters are also shifting from data lakes based on homegrown scripts and code to open standards and open formats, and they are beginning to embrace the structured data-processing functionality that supports data lakehouse capabilities. These trends are driving the evolution of vendor product offerings and strategies, as typified by Cloudera’s recent launch of Cloudera Data Platform (CDP) One, described as a data lakehouse software-as-a-service (SaaS) offering.
Cloudera is no stranger to large-scale data processing. The company was founded in 2008 to build a business around the Apache Hadoop data-processing framework and other associated open-source projects. Cloudera enjoyed a rapid rise thanks to high levels of interest (and hype) around Hadoop and big data, culminating in its initial public offering on the New York Stock Exchange in 2017. The company later merged with Hortonworks, its primary Hadoop-related rival, in 2019 amid wider market consolidation as hype gave way to more realistic expectations about the achievable benefits from big data projects. Both Cloudera and Hortonworks had already begun the long-term evolution of their product offerings, placing greater emphasis on business use cases, such as data warehousing, stream data processing, machine learning (ML) and data engineering, rather than the various open-source projects that enable them. In keeping with wider industry trends, Cloudera has also emphasized cloud-based deployments post-merger, including support for cloud object storage, and the potential advantages of its Cloudera Data Platform (CDP) as an analytic or operational data platform that can span multiple cloud providers as well as on-premises private cloud deployments as part of a hybrid cloud architecture. The company recently announced the launch of its CDP One data lakehouse SaaS offering, completing a significant engineering effort that was accelerated by its acquisition by investment firms Clayton, Dubilier & Rice and KKR for $5.3 billion in June 2021, as well as its simultaneous purchase of cloud-native data integration provider Datacoral and cloud data lake specialist Cazena. Cloudera is well established as a primary data platform provider whose customers include many Fortune 500 companies in industries such as financial services, retail, healthcare, telecommunications, manufacturing, energy/utilities, and government. The CDP One offering is designed to facilitate adoption of SaaS consumption models amongst those existing customers, as well as accelerate adoption among late adopters and small-to-medium companies looking for a more self-service, managed approach that does not rely on the need for large teams of data engineers with deep technical expertise to configure, deploy and manage data platforms and the associated infrastructure.
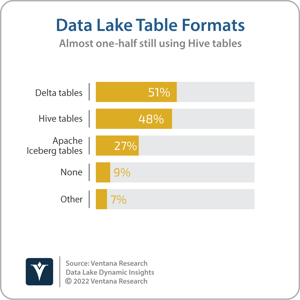
 The term data lakehouse is used to describe an environment in which the functionality associated with data warehousing is integrated into the data lake environment. Data lakehouse environments combine structured data processing and analytics acceleration technologies — such as distributed SQL query engines; support for atomic, consistent, isolated and durable transactions; updates and deletes; and concurrency control — with cloud object storage. This combination enables support for multiple business intelligence (BI) projects as well as data science and even operational applications based on data in cloud object storage, and it is one approach to what we call hydroanalytics. I assert that by 2024, more than three-quarters of current data lake adopters will be investing in data lakehouse technologies to improve the business value from accumulated data. Cloudera’s CDP One is significant in not only being the company’s first offering branded as a data lakehouse but also in being the first offering to be delivered and consumed as a SaaS service. The first point is important in that it sees the company delivering cloud compute, storage, ML, streaming analytics, and security and governance in a single SaaS offering. The second point is important in that it should enable the company to reach new customers that want to access these capabilities without the need for large IT teams to handle infrastructure management and operations, accelerating time to insight and enabling data practitioners to focus on data ingestion, data management, analytics and data science. CDP One delivers what Cloudera refers to as a Zero Ops experience in which cloud infrastructure, security and monitoring are managed by Cloudera, enabling data practitioners and developers to focus on data ingestion and management to support self-service analytics and exploratory data science. CDP One provides a single interface with services that enable practitioners to ingest, prepare and query data using SQL, as well as Python or R. Under the covers of the SaaS offering is Cloudera’s existing SDX (Shared Data Experience) functionality for identity and network management, as well as encryption, authentication and authorization, data lineage, and data governance. CDP One also includes support for the Apache Iceberg table format, which was previously added to CDP Public Cloud earlier this year. Iceberg is an open-source transaction management project providing support for updates and deletes and full schema evolution, which has the potential to increase the use of data lakes to support data warehousing workloads. The existing Apache Hive project provides table management functionality, but this is tightly coupled with the Hive query engine functionality. Ventana Research’s Data Lakes Dynamics Insights research highlights growing adoption of emerging table formats, such as Apache Hudi, Apache Iceberg and Delta Lake, that provide transaction management independent of the query engine. More than one-half of data lake adopters (57%) are using at least one of these emerging table formats today, and more than one-quarter (27%) are using Apache Iceberg.
The term data lakehouse is used to describe an environment in which the functionality associated with data warehousing is integrated into the data lake environment. Data lakehouse environments combine structured data processing and analytics acceleration technologies — such as distributed SQL query engines; support for atomic, consistent, isolated and durable transactions; updates and deletes; and concurrency control — with cloud object storage. This combination enables support for multiple business intelligence (BI) projects as well as data science and even operational applications based on data in cloud object storage, and it is one approach to what we call hydroanalytics. I assert that by 2024, more than three-quarters of current data lake adopters will be investing in data lakehouse technologies to improve the business value from accumulated data. Cloudera’s CDP One is significant in not only being the company’s first offering branded as a data lakehouse but also in being the first offering to be delivered and consumed as a SaaS service. The first point is important in that it sees the company delivering cloud compute, storage, ML, streaming analytics, and security and governance in a single SaaS offering. The second point is important in that it should enable the company to reach new customers that want to access these capabilities without the need for large IT teams to handle infrastructure management and operations, accelerating time to insight and enabling data practitioners to focus on data ingestion, data management, analytics and data science. CDP One delivers what Cloudera refers to as a Zero Ops experience in which cloud infrastructure, security and monitoring are managed by Cloudera, enabling data practitioners and developers to focus on data ingestion and management to support self-service analytics and exploratory data science. CDP One provides a single interface with services that enable practitioners to ingest, prepare and query data using SQL, as well as Python or R. Under the covers of the SaaS offering is Cloudera’s existing SDX (Shared Data Experience) functionality for identity and network management, as well as encryption, authentication and authorization, data lineage, and data governance. CDP One also includes support for the Apache Iceberg table format, which was previously added to CDP Public Cloud earlier this year. Iceberg is an open-source transaction management project providing support for updates and deletes and full schema evolution, which has the potential to increase the use of data lakes to support data warehousing workloads. The existing Apache Hive project provides table management functionality, but this is tightly coupled with the Hive query engine functionality. Ventana Research’s Data Lakes Dynamics Insights research highlights growing adoption of emerging table formats, such as Apache Hudi, Apache Iceberg and Delta Lake, that provide transaction management independent of the query engine. More than one-half of data lake adopters (57%) are using at least one of these emerging table formats today, and more than one-quarter (27%) are using Apache Iceberg.
 Cloudera has been through some significant changes in recent years. The company previously added new and additional functionality to its CDP Public Cloud and CDP Private Cloud offerings to better position itself to address a broader range of workloads and deployments. The company has functionality to cover a wide spectrum of objectives, including data engineering, data management, data governance, data processing (both operational and analytic), data streaming, visualization, and data science. The existing CDP Private Cloud and CDP Public Cloud enable self-managed adoption of these capabilities on-premises and in the cloud as well as the associated requirements for the configuration and management of both software and associated hardware. As such, organizations could be forgiven for thinking that Cloudera is only for companies with highly skilled operations teams. CDP One expands the company’s addressable market by offering the same breadth of functionality but in a consumable SaaS consumption model designed to facilitate self-service for organizations and departments without significant operational resources, enabling the prioritization of data and analytics. I recommend that all organizations consider Cloudera when evaluating their options for large-scale data processing and analytics initiatives.
Cloudera has been through some significant changes in recent years. The company previously added new and additional functionality to its CDP Public Cloud and CDP Private Cloud offerings to better position itself to address a broader range of workloads and deployments. The company has functionality to cover a wide spectrum of objectives, including data engineering, data management, data governance, data processing (both operational and analytic), data streaming, visualization, and data science. The existing CDP Private Cloud and CDP Public Cloud enable self-managed adoption of these capabilities on-premises and in the cloud as well as the associated requirements for the configuration and management of both software and associated hardware. As such, organizations could be forgiven for thinking that Cloudera is only for companies with highly skilled operations teams. CDP One expands the company’s addressable market by offering the same breadth of functionality but in a consumable SaaS consumption model designed to facilitate self-service for organizations and departments without significant operational resources, enabling the prioritization of data and analytics. I recommend that all organizations consider Cloudera when evaluating their options for large-scale data processing and analytics initiatives.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








