
I have previously written about the importance of data democratization as a key element of a data-driven agenda. Removing barriers that prevent or delay users from gaining access to data enables it to be treated as a product that is generated and consumed, either internally by employees or externally by partners and customers. This is particularly important for organizations adopting the data mesh approach to data ownership, access and governance. Data mesh is an organizational and cultural approach to data, rather than a technology platform. Nevertheless, multiple vendors are increasingly focused on providing products that facilitate adoption of data mesh and promote data democratization. Amazon Web Services is one such vendor, thanks to the recent launch of Amazon DataZone, one of the figurehead analytics and data announcements made during the company’s recent re:Invent customer event.
Few trends have had a bigger impact on the computing landscape in recent decades than the emergence of cloud computing. Having pioneered the concept, Amazon Web Services was initially created to support the e-commerce requirements of Amazon.com but began making its services available to other organizations in 2006 and now offers more than 200 cloud services to millions of customers from data centers, providing 99 availability zones in 31 regions around the globe. Analytics and data form an integral part of the AWS cloud services portfolio, with the company providing multiple services addressing data platform, data management, analytics and machine learning (ML) requirements. AWS has always emphasized the benefits of customer choice: It has 11 different databases in its cloud databases portfolio as well as more than 20 data processing, data management, analytics and ML services in its analytics portfolio. Integrating and governing data dispersed across multiple services, availability zones and regions can be a challenge, however, and during the company’s re:Invent technology event in late 2022, there was an increased emphasis on unifying capabilities to reduce operational complexity, such as easier integration between Amazon Aurora and Amazon Redshift, improved integration with Apache Spark for Amazon Athena and Amazon Redshift, and the launch of Amazon DataZone.
The Amazon DataZone data catalog is designed to enable the management of, and self-service access to, data throughout an organization. That includes not only AWS’ cloud services but also other cloud and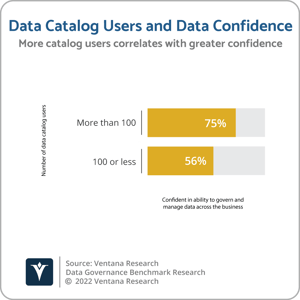 on-premises data centers. For organizations committed to AWS as a cloud provider, Amazon DataZone could potentially provide a higher-level catalog of all services, enabling a reduction of data silos. The product is aimed at data administrators and data stewards responsible for managing and governing data, as well as data consumers (analysts, data scientists, decision-makers and other business users) who need access to data. It is designed to serve as a centralized catalog that facilitates the democratization of data across an organization. As I have previously explained, the data catalog has become indispensable for good data governance. Ventana Research’s Data Governance Benchmark Research highlights that the more data catalog users an organization has, the greater the trust the organization has in its data and the higher the level of confidence in the organization’s ability to govern and manage data across the business. Three-quarters of organizations (75%) with more than 100 data catalog users are confident in their organization’s ability to govern and manage data across the business, compared to 56% of organizations with 100 or less data catalog users. Amazon DataZone provides a web interface through which data professionals can define data taxonomies, configure governance policies, connect to data sources and publish datasets. The product utilizes ML functionality to identify metadata that is used to facilitate search and discovery of published datasets for data consumers, who can also use Amazon DataZone to request access to data. Once approved, data consumers create data products called Amazon DataZone Data Projects, to which they can share access for collaboration.
on-premises data centers. For organizations committed to AWS as a cloud provider, Amazon DataZone could potentially provide a higher-level catalog of all services, enabling a reduction of data silos. The product is aimed at data administrators and data stewards responsible for managing and governing data, as well as data consumers (analysts, data scientists, decision-makers and other business users) who need access to data. It is designed to serve as a centralized catalog that facilitates the democratization of data across an organization. As I have previously explained, the data catalog has become indispensable for good data governance. Ventana Research’s Data Governance Benchmark Research highlights that the more data catalog users an organization has, the greater the trust the organization has in its data and the higher the level of confidence in the organization’s ability to govern and manage data across the business. Three-quarters of organizations (75%) with more than 100 data catalog users are confident in their organization’s ability to govern and manage data across the business, compared to 56% of organizations with 100 or less data catalog users. Amazon DataZone provides a web interface through which data professionals can define data taxonomies, configure governance policies, connect to data sources and publish datasets. The product utilizes ML functionality to identify metadata that is used to facilitate search and discovery of published datasets for data consumers, who can also use Amazon DataZone to request access to data. Once approved, data consumers create data products called Amazon DataZone Data Projects, to which they can share access for collaboration.
Amazon DataZone is well-aligned with the four key principles of the data mesh concept: domain-oriented ownership, data as a product, self-serve data infrastructure and federated governance. Amazon DataZone utilizes the existing AWS Glue Data Catalog functionality offered via its AWS Glue data integration service, which provides a central metadata repository aimed specifically at data professionals. A key differentiator between the two offerings is Amazon DataZone’s functionality that enables business teams to create data products. I assert that through 2026, almost all organizations using data catalog products will increase business user access, facilitating self-service data discovery and accelerating data democratization initiatives. At re:Invent, AWS also announced (amongst very many other things) the preview release of AWS Glue Data Quality, based on the Deequ open-source library, providing automated data quality monitoring and management of Amazon S3 data lakes and AWS Glue data pipelines as well as Amazon Athena for Apache Spark, enabling users of AWS’ serverless interactive query service to process data using Apache Spark without provisioning, configuring and scaling resources. AWS also announced the preview of Amazon Redshift integration with Apache Spark, enabling users to run Apache Spark jobs on data in the data warehousing service, as well as “zero-ETL” integration between the Amazon Aurora operational database and Amazon Redshift analytic database. The offering is designed to provide continuous replication of operational data from Amazon Aurora to Amazon Redshift and then utilize the data warehouse service to transform the data, as required, for analysis.
utilizes the existing AWS Glue Data Catalog functionality offered via its AWS Glue data integration service, which provides a central metadata repository aimed specifically at data professionals. A key differentiator between the two offerings is Amazon DataZone’s functionality that enables business teams to create data products. I assert that through 2026, almost all organizations using data catalog products will increase business user access, facilitating self-service data discovery and accelerating data democratization initiatives. At re:Invent, AWS also announced (amongst very many other things) the preview release of AWS Glue Data Quality, based on the Deequ open-source library, providing automated data quality monitoring and management of Amazon S3 data lakes and AWS Glue data pipelines as well as Amazon Athena for Apache Spark, enabling users of AWS’ serverless interactive query service to process data using Apache Spark without provisioning, configuring and scaling resources. AWS also announced the preview of Amazon Redshift integration with Apache Spark, enabling users to run Apache Spark jobs on data in the data warehousing service, as well as “zero-ETL” integration between the Amazon Aurora operational database and Amazon Redshift analytic database. The offering is designed to provide continuous replication of operational data from Amazon Aurora to Amazon Redshift and then utilize the data warehouse service to transform the data, as required, for analysis.
The high number of different data and analytics services in the AWS portfolio provides customers with a broad range of choices but can also result in a complex web of services that can be difficult to manage holistically. The introduction of Amazon’s DataZone is important in providing a unifying environment for data access and management and will facilitate the ability of AWS customers to govern and manage data across the business and improve access to data through data mesh initiatives. I recommend that all AWS customers using multiple data services evaluate the potential benefits of Amazon DataZone alongside other data catalog products and services.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








